
Neurosymbolic Data Agents
I’m working on building agents that leverage LLMs in conjunction with symbolic representations of analytics and data to answer complex, data-intensive questions. More details coming soon.
Jan 8, 2026

RingSQL - Synthetic Data Generation for Text-to-SQL
Recent advances in text-to-SQL systems have been driven by larger models and improved datasets, yet progress is still limited by the scarcity of high-quality training data. Manual data creation is expensive, and existing synthetic methods trade off reliability and scalability. Template-based approaches ensure correct SQL but require schema-specific templates, while LLM-based generation scales easily but lacks quality and correctness guarantees. We introduce RingSQL, a hybrid data generation framework that combines schema-independent query templates with LLM-based paraphrasing of natural-language questions. This approach preserves SQL correctness across diverse schemas while providing broad linguistic variety. In our experiments, we find that models trained using data produced by RingSQL achieve an average gain in accuracy of +2.3% across six text-to-SQL benchmarks when compared to models trained on other synthetic data.
Jan 7, 2026
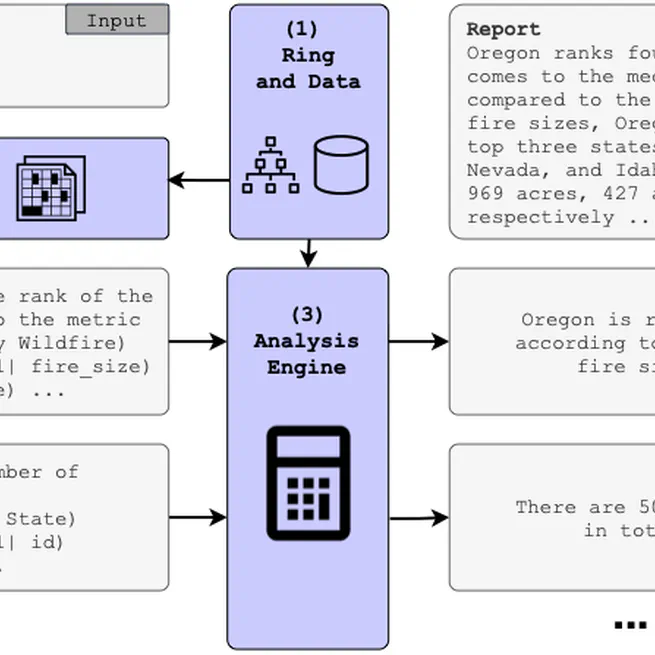
Satyrn - Report Generation
A data platform that uses analytics augmented generation to write comprehensive reports grounded by your data.
Jun 17, 2024

Multi-Domain Text Summarization Evaluation
Existing literature does not give much guidance on how to build the best possible multi-domain summarization model from existing components. We present an extensive evaluation of popular pre-trained models on a wide range of datasets to inform the selection of both the model and the training data for robust summarization across several domains. We find that fine-tuned BART performs better than T5 and PEGASUS, both on in-domain and outof-domain data, regardless of the dataset used for fine-tuning. While BART has the best performance, it does vary considerably across domains. A multi-domain summarizer that works well for all domains can be built by simply fine-tuning on diverse domains. It even performs better than an in-domain summarizer, even when using fewer total training examples. While the success of such a multi-domain summarization model is clear through automatic evaluation, by conducting a human evaluation, we find that there are variations that can not be captured by any of the automatic evaluation metrics and thus not reflected in standard leaderboards. Furthermore, we find that conducting reliable human evaluation can be complex as well. Even experienced summarization researchers can be inconsistent with one another in their assessment of the quality of a summary, and also with themselves when reannotating the same summary. The findings of our study are two-fold. First, BART fine-tuned on heterogeneous domains is a great multidomain summarizer for practical purposes. At the same time, we need to re-examine not just automatic evaluation metrics but also human evaluation methods to responsibly measure progress in summarization.
Dec 6, 2023

MimIR
Mim is an information retrieval system used for answering complex questions over large document corpora.
Nov 1, 2022

Natural Language Notebook
The U.S. court system is the nation’s arbiter of justice, tasked with the responsibility of ensuring equal protection under the law. But hurdles to information access obscure the inner workings of the system, preventing stakeholders – from legal scholars to journalists and members of the public – from understanding the state of justice in America at scale. There is an ongoing data access argument here: U.S. court records are public data and should be freely available. But open data arguments represent a half-measure; what we really need is open information. This distinction marks the difference between downloading a zip file containing a quarter-million case dockets and getting the real-time answer to a question like “Are pro se parties more or less likely to receive fee waivers?” To help bridge that gap, we introduce a novel platform and user experience that provides users with the tools necessary to explore data and drive analysis via natural language statements. Our approach leverages an ontology configuration that adds domain-relevant data semantics to database schemas to provide support for user guidance and for search and analysis without user-entered code or SQL. The system is embodied in a “natural-language notebook” user experience, and we apply this approach to the space of case docket data from the U.S. federal court system. Additionally, we provide detail on the collection, ingestion and processing of the dockets themselves, including early experiments in the use of language modeling for docket entry classification with an initial focus on motions.
Jun 21, 2021
Critical Resource Exchange
As part of the C3 Lab, we built a tool for evaluating and responding to requests for essential resources in emergency situations. Crises, such as the ongoing coronavirus pandemic, require extraordinary mobilization of expertise and resources beyond what established networks and policies can provide. Credible information and open communication are foundational to mounting a proper response, so we developed both an exchange, for sharing and obtaining critical resources, and a dashboard, for illustrating where and which needs are most pressing. Organizations and policymakers armed with these tools can make better decisions about allocations and interventions - whatever the issue at hand may be.
Apr 2, 2020