About Me
I am a computer science PhD candidate at Northwestern University in the C3 Lab advised by Kristian Hammond. My research focuses on leveraging AI and large language models (LLMs) to automate data science processes, enabling users to ask questions of their data and receive meaningful, contextualized insights.
Specifically, this involves:
- Modeling and representing data science knowledge so that the system understands the range of actions it can take to perform data analytics.
- Building mechanisms and tools for extracting information from databases, which includes training and developing text-to-query models capable of answering atomic questions.
- Developing reasoning and planning methods that utilize the available data analytics knowledge and tools to provide contextualized answers to users’ inquiries.
Interests
- Artificial Intelligence
- Question Answering
- Neurosymbolic AI
- Language Generation
Education
PhD Computer Science
Northwestern University
MS Computer Science
University of Southern California
BS Computer Science
Idaho State University
News
- January 2026: The preprint for our paper on generating high quality synthetic training data for text-to-SQL is available on arXiv.
- September 2025: I finished my internship at IBM Research. Thank you to my mentors Michael Glass, Nhan Pham, and Shankar Subramanian for an excellent summer of research!
- June 2025: I’m excited to be starting an internship at IBM Research for the summer working on LLMs for data research.
- November 2024: I presented the Satyrn paper at EMNLP 2024.
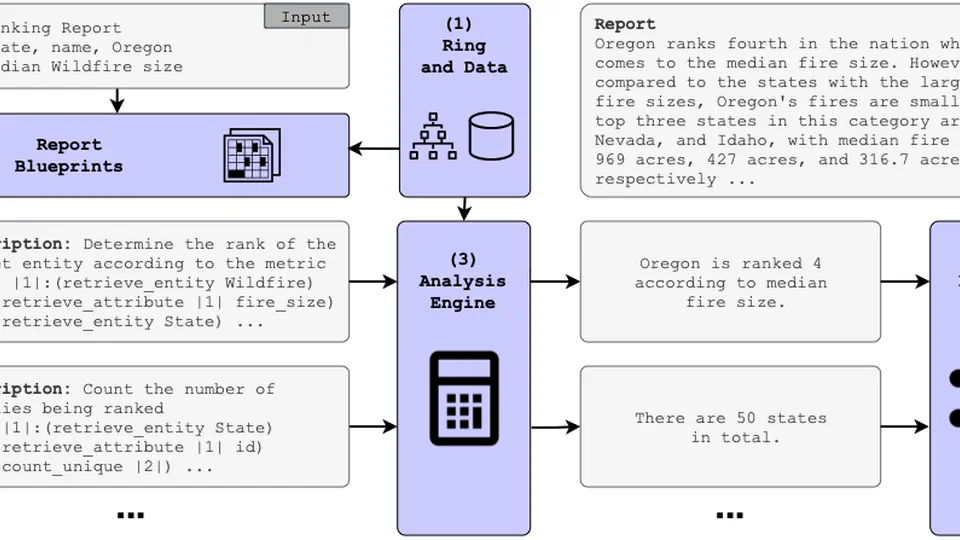
- September 2024: Our paper Satyrn: A Platform for Analytics Augmented Generation was just accepted to EMNLP 2024. See you in Miami!
- June 2024: I partcipated in the CASMI workshop “AI Safety: A Domain-Focused Approach to Anticipating Harm.” Read the full report.
Publications
(2026).
RingSQL: Generating Synthetic Data with Schema-Independent Templates for Text-to-SQL Reasoning Models.
Preprint.
(2024).
Satyrn: A Platform for Analytics Augmented Generation.
Empirical Methods in Natural Language Processing 2024 (EMNLP 2024 Main).
(2023).
Lightweight Knowledge Representations for Automating Data Analysis.
arXiv preprint arXiv:2311.12848.
(2023).
Multi-domain Summarization from Leaderboards to Practice: Re-examining Automatic and Human Evaluation.
Proceedings of the Third Workshop on Natural Language Generation, Evaluation, and Metrics (GEM).
(2021).
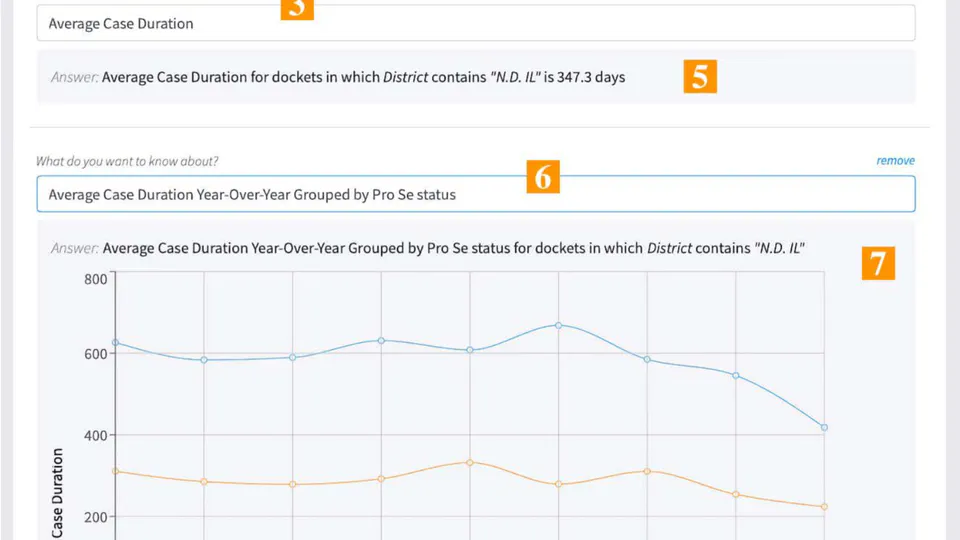
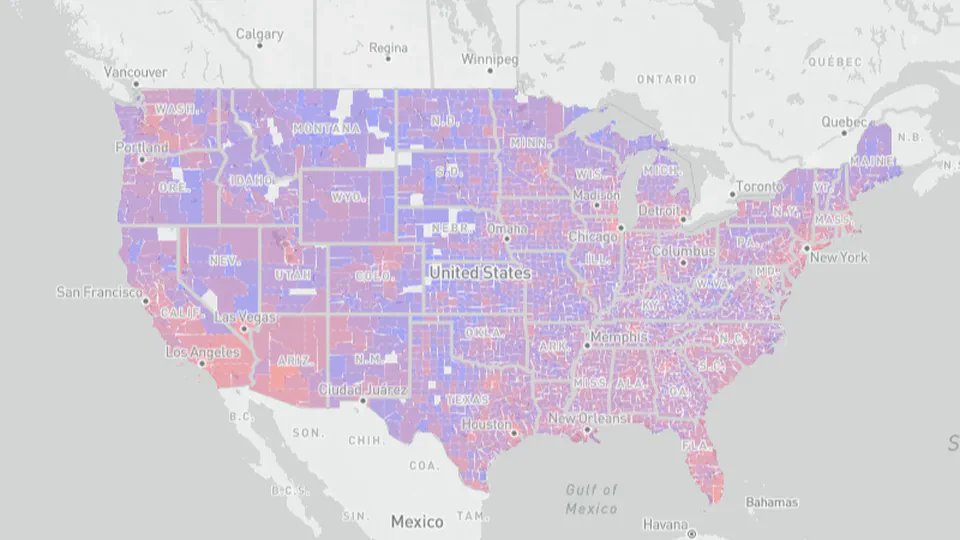
From Data to Information: Automating Data Science to Explore the US Court System.
Proceedings of the Eighteenth International Conference on Artificial Intelligence and Law (ICAIL 2021).
(2021).
Requirements for Open Political Information: Transparency Beyond Open Data.
arXiv preprint arXiv:2112.03119.
(2018).
GPGPU Enabled Ray Directed Adaptive Volume Visualization for High Density Scans.
Proceedings of the Practice and Experience on Advanced Research Computing (PEARC).
Experience
Research Intern
IBM ResearchResearch Assistant
Northwestern UniversityResearch Intern
Lawrence Livermore National LaboratoryResearch Intern
Idaho National Laboratory
Projects




Teaching

